LLMs Part 3: Other Considerations for Practical Usage
llms strategy tutorial finance Evaluation and Close Source Moats
A generally accepted method for evaluating LLMs is on benchmarks. A few notable ones include MMLU, BIG-bench, and HELM. In finance, there are not many publicly available, two examples are the Financial PhraseBank and FiQA. The recent advances occurred at such a breakneck speed that the tests have not caught up. The evaluation tests are all imperfect given the difficulty in evaluating human experience. This is what truly separates some of the open and closed source models. OpenAI’s models have taken a particularly careful approach to this. LLMs suffer from hallucination, toxicity, and stereotypes, all which are difficult to measure with a specific test. From a commercial perspective, the old phrase “Nobody gets fired for going with IBM” might apply here and reinforce the closed source model.
Open Source, Proprietary Models & Reduced Parameters
There is much debate about the utility of closed source LLM APIs versus the open-source versions. A "leaked" memo from Google highlights the bull case (and corresponding existential corporate threat) for open source, while some experts here and here explain the gap between closed and open source will remain large. Nonetheless, large foundational models benefit from fine-tuning when tackling specific tasks. In March 2023, the Meta model LLaMA was leaked, making the partially open sourced foundational model available to the masses. Since, it has provided a good demonstration of different approaches to fine-tuning. At 7B parameters, it is lighter than the closed source models and thus implementable and practical with regards to training and inference. The license is restrictive for commercial use, but it is likely that the parameters for an open source model will be available at some point in the near future.
With that in mind, there are three ways to use an open sourced model. First, using the LLM out of the box. The challenge here is that most models will perform poorly. Second, fine tuning the open source model to solve a specific problem. While it will perform better, the challenge is that these models can be large, resulting in engineering challenges in training and inference. Third, a technique known as Parameter-Efficient Fine Tuning (PEFT) can be used. PEFT facilitates the adaptation of LLMs without the need to update all the parameters. Low-Rank adaptation (LORA) and Adapters are two PEFT methods that decrease the cost of training and maintenance and make the models more amenable to practical usage. There are good arguments that lower rank open source models fine tuned for specific tasks will outperform the larger models.
An example of the different cases on LLaMA are below. LLaMA itself would be the first case described above. Alpaca is the second case (fine tuning an open source model), while LLaMA-Adapter and Alpaca-Lora are the third case (lighter weight model using PEFT technique).
- Alpaca: Updates all 7B parameters of LLaMA, at a reasonable cost of ~$500 compared with the multi-million dollar spend for GPT. “Alpaca is a language model fine-tuned using supervised learning from a LLaMA 7B model on 52K instruction-following demonstrations generated from OpenAI’s text-davinci-003.”
- LLaMA-Adapter: Inserts adapter layers on top of the model. Adapters increases efficiency by keeping the pretrained model frozen and only tunes a small number of parameters added to the model.
- Alpaca-Lora: Low Rank Adaptation (LoRA) decomposes the model weight matrices using low-rank decomposition. It introduces a trainable rank decomposition into each later. So, LoRA increases finetuning performance by reducing parameter numbers
Datasets
As mentioned in the previous section, having a real “moat” in LLM development is debatable (but still possible!). The mere plausibility of the heavily funded companies having a thin advantage is a testament to how incredible the open source community is. This section gives some high level appreciation of what is available to the general public. Outside of compute power, the biggest challenge is having access to pre-training data in order to train an LLM and then instruction tuning data to further enhance the value.
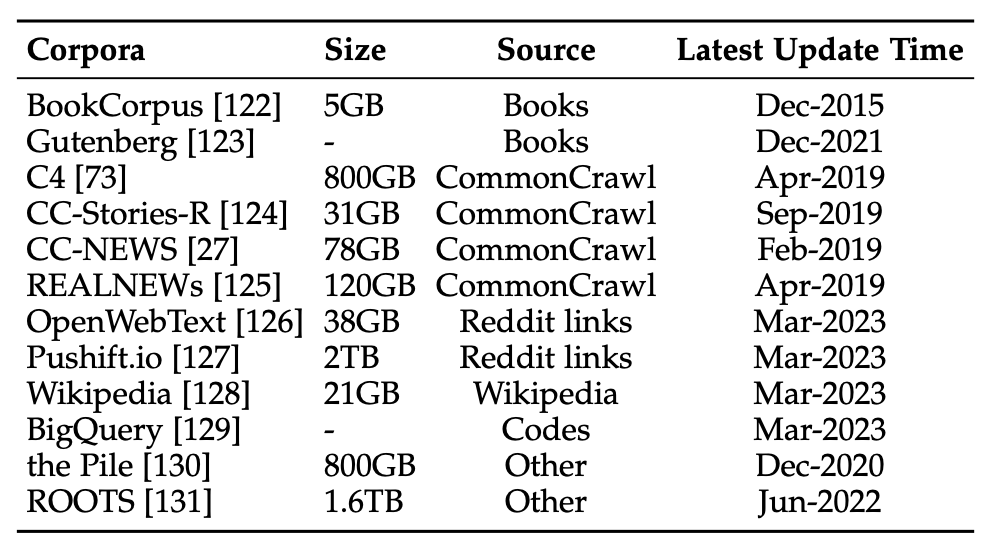
Below is a table (excerpted from the Survey paper) of open source datasets that is commonly used among LLMs. Many sites tabulate hundreds of datasets in all different languages that are accessible. Moreover, many sources require scrubbing because of duplication and other issues. For example, Red Pajama (named after a children’s book that begins with the open source LLaMA: Llama, Llama, Red Pajama).
Instruction tuning is considered a barrier given the high touch nature of the dataset. It was thought to require humans to write instructions and answer them in order to form the training dataset. It was shown with Self-Instruct that it is possible to bootstrap LLMs to generate this dataset on its own, with performance on par with state of the art. Databricks Dolly 15k and Open-Assistant Conversations are two open source instruction tuning datasets that standout.
Not Covered, But Important!
Prompt Engineering. A large and important topic because it is essentially the interface for using Generative LLMs. There are courses and guides.
Regulations & Legal Risks. Behind the curve on guidance from the experts.