LLMs Part 2: Financial Markets Use Cases
llms strategy tutorial finance Overview
There are three broad categories of practical use cases in NLP: language generation, knowledge utilization, and complex reasoning. Out of all the industries, identifying meaningful use cases that impact the Financial Markets business is particularly difficult because of non-stationarity and alpha decay, which is common to most financial problems. In any industry, having a rubric to determine the nature of the problem is the first step and described in the first section.
Next follows two sections for each use case category type of leveraging the technology as efficiency tools and investment enhancement tools, which are subsets of the broader themes. In addition, a few thoughts on multi-modal use cases that go beyond pure language as an input. The starred (*) use cases benefit from knowledge of prompt engineering, which has its own section given the relative importance.
Finally, a section on Embeddings and Code Generation given their practical and active impact.
A Rubric
Thinking through the different use cases, there are several considerations when using LLMs in practice:
Specificity of the task: Specificity ranges from generalized to specific. LLMs excel at generalized problems. However, they can underperform models for specific tasks. There are several cases where fine-tuning a model shows improvement for medicine, finance and law. Cases where generalized models work best include knowledge intensive tasks, most generation tasks that require creativity, dealing with out-of-distribution data and where limited annotated data is available. An example of specific tasks in the financial domain is Bloomberg’s LLM model called BloombergGPT.
Value-add of the task: Highly correlated to specificity of the task. There is a good argument that for high value-add tasks, specialized AI systems are better than general systems. This is because of the need for higher accuracy and more stringent requirements for a specialized task. The paradox is that these specialized tasks are fewer than the general ones, but have higher impact. The corollary is that consolidation of models to a few ‘super’ intelligent AI models owned by a few companies is unlikely.
Closed-source vs Open-source: Ranges from using closed source, black box APIs to internal or proprietary development of bespoke models. Cost, reproducibility and control are issues to consider. Cost influences both channels: closed source solutions might increase their cost per API call; open source solutions will need a team and infrastructure. Reproducibility and control are limitations with closed source systems, sometimes mitigated by versioning by the vendor.
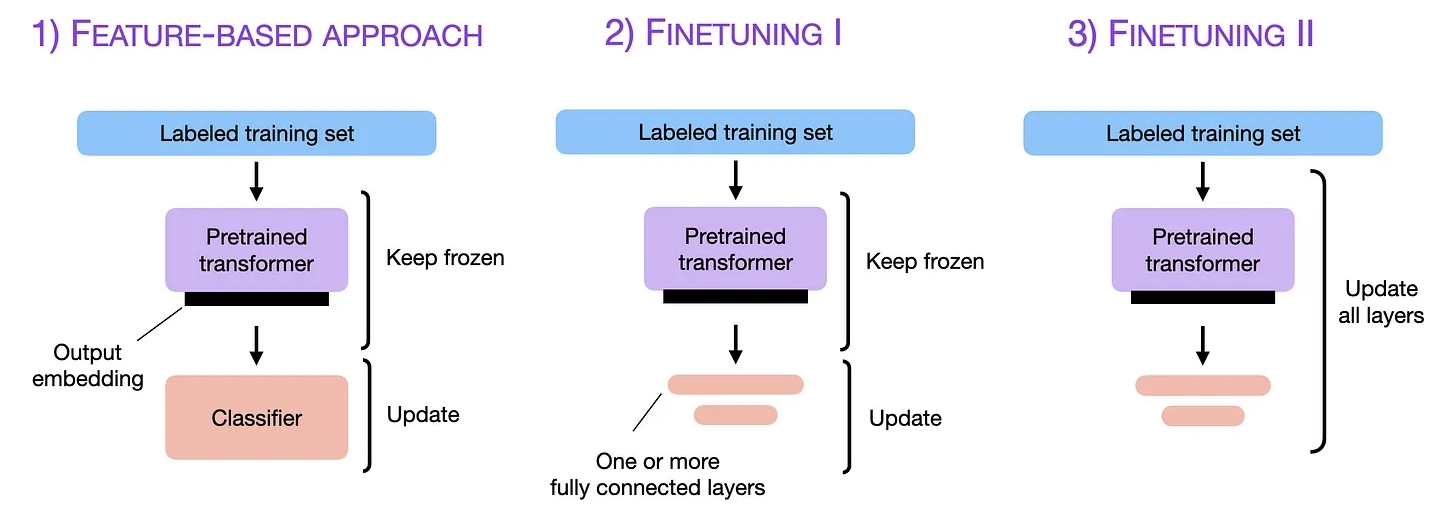
Text generation input vs feature embeddings: Generative APIs eliminate the need for intermediate preprocessing of language, which can be a challenging and costly step, because the API/model can interact directly with text. On the other end of the spectrum, embeddings can be used as features in the classical prediction system paradigm, eg building a classifier on top of the embedding output. An example of how this paradigm is implemented is in the left hand side of the figure below.
As Efficiency Tools
- Text Generation*. Many users are familiar with this feature popularized by ChatGPT. This area can improve the efficiency of knowledge workers, including the use of an assistant, idea generation and coding. The immediate impact on coding is very significant and described in a little more detail in its own section below.
- Text Summarization*. There are two types of summarization: abstract and extractive. Abstract summarization refers to creating new text that consolidates the original. Extractive references specific facts within the text. Both could be useful for PMs that are inundated with sell-side content. Instead of covering N securities, they can potentially use this as an efficiency tool to cover 10*N securities.
- Rewriting. This includes editing existing documents and translation. PMs potentially miss content from experts that write in different languages. Notably, the appetite for information within Asian markets makes this appealing. LLMs are particularly strong at translation tasks, as this is what the architecture of Transformers are originally designed to do.
- Search. Search traditionally leverages knowledge graphs and page rank. LLMs can handle longer queries and understand the user intent to pull more relevant information. As we think about growing database schemas, search becomes particularly reliant on robust cataloging. While a slightly different problem, product search is a common use case in the retail industry.
- Question Answering. Daisy chaining LLMs for search and summarization.
As Investment Enhancement Tools
- Extraction*. Potentially a useful tool in the generation of novel financial datasets by taking financial texts (S1s, earnings transcripts, news articles, etc) and extracting key information in a formatted way. For example, SPACs were popular ~2 years ago and it was common for an analyst to manually pull the relevant event dates from S1s or depend on vendor products with a variance in quality. Using LLMs, this could be a relatively trivial task to construct. Other examples of extraction are sell side catalyst calendars, bond and IPO prospectuses and of course earnings call transcripts.
- Clustering. This is a classical dimensional reducing technique that can be extended and enhanced using available embeddings. This allows for ways to group together bodies of text (and potentially table schemas) that might be relevant.
- Classification. This can be done via a traditional supervised learning approach, where the classifier is trained on the embeddings, or via a few-shot approach, where prompt engineering is used to provide examples to a LLM that then learns how to do the classification. One example is sentiment analysis.
- Anomaly detection, diversity measurement and recommendations.Embeddings encode relationships within a dataset. Anomalies, by definition, are data points that exist outside close relationships. Hence, LLMs, which encode large corpuses can be used for anomaly detection. Similarly, diversity and recommendations leverage a similar mechanism.
Beyond Language: Multimodal
Given that most financial markets businesses already run on structured data, it is relevant to consider how text plus tabular data can be used. An example is document analysis, where it is possible to parse layout and extract key information for various documents such as scanned forms and academic papers. Multi-model development is the current frontier, with ImageBind from Meta claiming to combine six modalities into a single embedding space.
Code Generation
One of the strongest use cases having an immediate impact is in code generation. Example models include Github Copilot (Codex), Claude and Replit Code. The power of this use case cannot be underestimated, as it helps novices and experts alike. As an illustration to non-coders on the power of LLMs as a coding partner, below is a brief enumeration gathered from here and here.
- Turning comments into code
- Complete a function, or complete next line of code
- SQL query generation
- Explain this code
- Editing and debugging code.
Embeddings
Embeddings are such a large topic that it deserves a separate in-depth teardown. OpenAI and Cohere are two example companies that offer embeddings that help tackle some of the natural language problems. Embeddings are becoming so pervasive that vector databases, like Pinecone, are specifically designed for embeddings and have become popular recently. This technique can enhance downstream tasks, such as search, clustering, recommendations, anomaly detection, and classification. This reference gives a nice comparison of open and closed embeddings including performance and cost.