RAG on 10K: Part 2
llms tutorial project Overview
In Part 1, I explained how to pre-process documents and create an index of embeddings. In Part 2, this post, I explain how to retrieve the subdocuments that are the most relevant to the target extraction. The relevant code is here, with the notebook called retrieval_extraction.ipynb running the script to follow along. The steps and outline for this post are:
- Retrieval
- Define the information to extract in the form of a question.
- Get the embedding for that question.
- Retrieve the sections of the 10K that is most semantically related.
- Extraction
- On each of the candidate sections extract using a Question Answering (QA) model and Masked Language Model (MLM).
- Ensemble the results to get a final value.
Retrieval
The first step is to define a query that can be embedded so that cosine similarity can pull the most relevant section (aka subdocument) from the 10K. I used: query = 'query: What is the name of the company?'. Note that for the 'intfloat/e5-small-v2' model, the 'query: ' needs to be prepended to the query text and 'passage: ' to the subdocument for it to be effective. Below is an example subdocument that is pulled with a cosine score of 0.71:
'passage: iPad\n\niPad® is the Company’s line of multipurpose tablets based on its iPadOS® operating system. The iPad line includes iPad Pro®, iPad Air®, iPad and iPad mini®.\n\nWearables, Home and Accessories\n\nWearables, Home and Accessories includes:\n\nAirPods®, the Company’s wireless headphones, including AirPods, AirPods Pro® and AirPods Max™; Apple TV®, the Company’s media streaming and gaming device based on its tvOS® operating system, including Apple TV 4K and Apple TV HD; Apple Watch®, the Company’s line of smartwatches based on its watchOS® operating system, including Apple Watch Ultra™, Apple Watch Series 8 and Apple Watch SE®; and Beats® products, HomePod mini® and accessories.\n\n•\n\n\n\n\n\nApple Inc. | 2022 Form 10-K | 1\n\nServices\n\nAdvertising\n\nThe Company’s advertising services include various third-party licensing arrangements and the Company’s own advertising platforms.\n\nAppleCare'This subdocument is the upper bound on how well extraction will perform. I like to do the human test: if a human looks at this, can they answer the question? In fact, this is not straightforward. A few issues. One, the characters like \n are distracting and may effect model performance. Two, there are many entity names that are brands and could be viable candidates. Moreover, the form of the query, which uses the word "company", might effect what subdocuments are highly ranked. See below for another response with score 0.72:
'passage: have a material adverse impact on the Company’s business, results of operations and financial condition.',By changing the query to
query = 'query: What should I name this company?', the top 2 of 3 hits are much more promising:
'passage: Apple Inc. | 2022 Form 10-K | 8'
'passage: Apple Inc. | 2022 Form 10-K | 7\n\nBusiness Risks\n\nTo remain competitive and stimulate customer demand, the Company must successfully manage frequent introductions and transitions of products and services.'
Extraction
After pulling about 20 subdocuments per 10K and per question, we use a model to extract from them using two approaches: Masked Language Modeling (MLM) and Question Answering (QA).
The MLM approach is to insert a mask into the question and apply the MLM model to predict the answer. I use the model 'bert-base-cased' and I use the question ". The name of the company is [MASK].". The results are not great at all.
The QA approach is to create a query and obtain an answer. I use the model 'distilbert-base-cased-distilled-squad' and I use the question "What is the name of the company?". Again the results are upper bounded by the quality of the subdocuments.
For the question on company name and the Apple 10K, we have 20 responses for each of the two embedding models. The final table with the 8 highest QA ranked for the e5 embedding model looks like this:
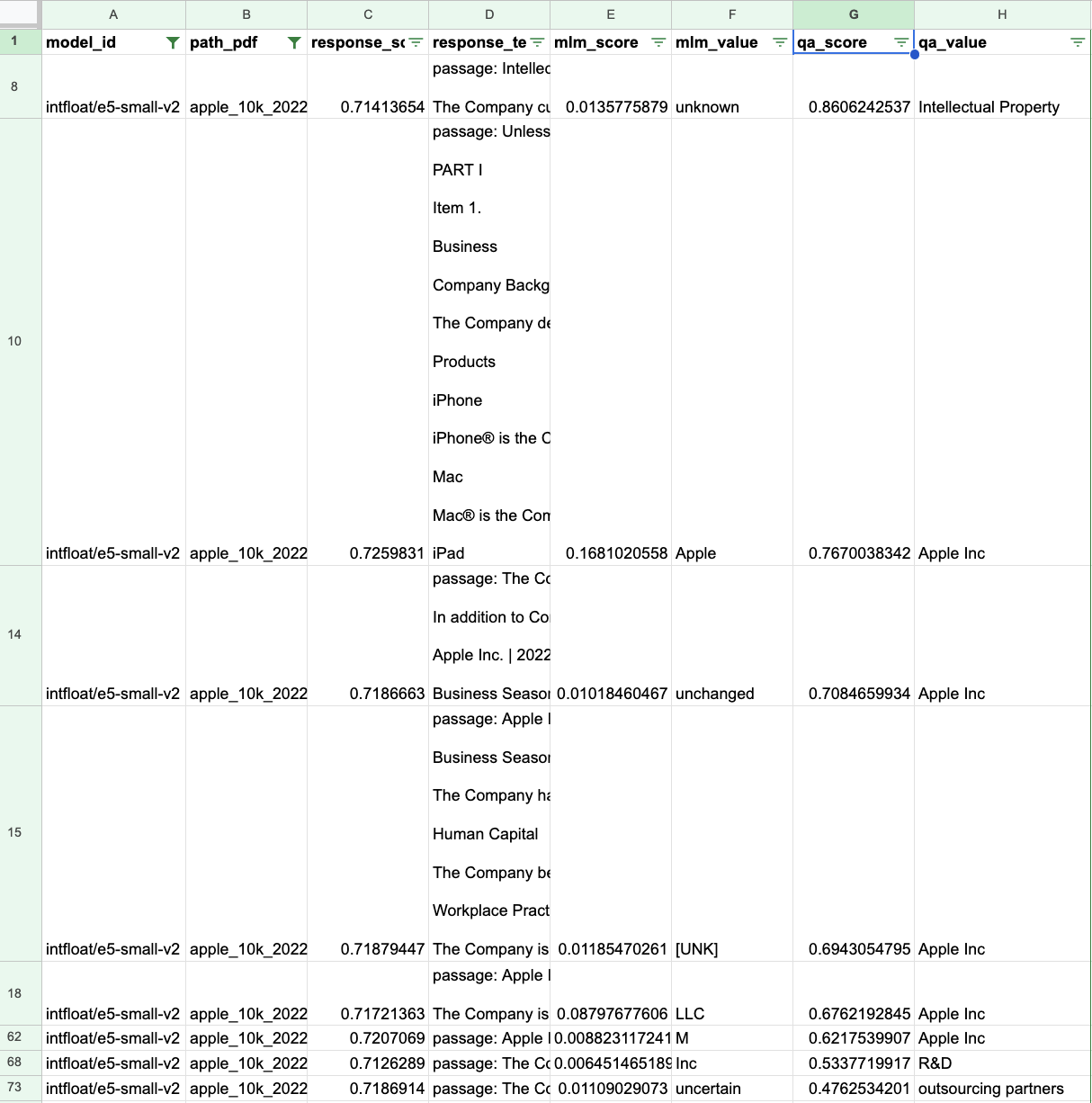
The final step is to do some ensembling and treatment of the results that are dependend on the question. For example, removing "Inc." from the company name and grouping by the answer for all scores greater than .60.