Pun Generator
machine-learning tutorial project mlops Revision
Before the pervasiveness of large language models, most NLP applications were intensive and retrospectively archaic. In the article below, I generated puns by converting the input terms and a collection of reference puns to phonemes and then the reference pun that has the closest distance between its phoneme represenation and the input phoneme is used. Given this required a set of calculations, I used some caching to save time. It worked well! However, now we can do this by simply going to ChatGPT and asking them to do it. I salvaged the project by converting the webpage to call ChatGPT instead.
Original Article
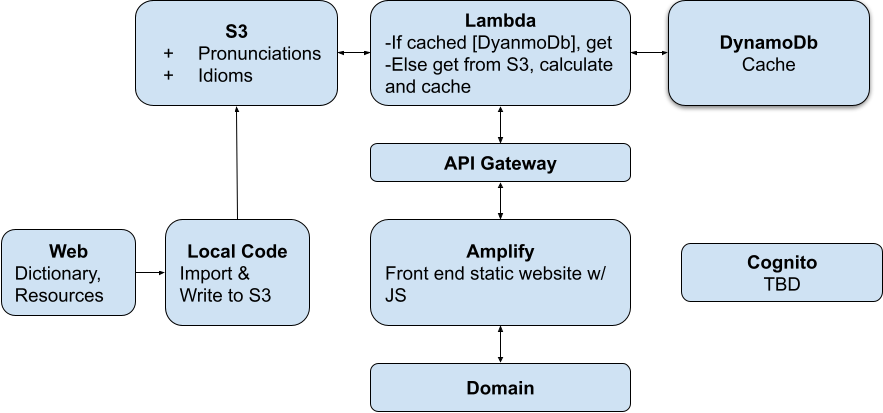
The serverless components of the Pun Generator Application are described in a another post. In this post, more detail on the methodology is described.
Briefly, the idea is to convert input word $x_{\text{word}}$ to its phoneme representation $x_{\text{phoneme}}$. Similarly, a set of reference puns $\{y_{\text{pun}}\}_i$ are converted to its phonemene representation $\{y_{\text{phoneme}}\}_i$, where $i$ indexes each pun. Then a function returns the ${y_{\text{pun}}}_j$ with the minimum value for the function dist($x_{\text{phoneme}}$, ${y_{\text{pun}}}_i$), where $dist$ is a distance function defined here as the Levenshtein distance.
A rudimentary algorithm, with limited to no error handling or enhancements. The code executes the following steps:
- Receives the input word. For now, not treatment to this word is performed. It does a look-up for a dictionary in S3 that converts the word to its pronunciation using the CMU dictionary.
- It checks DynamoDB to see if the word has been searched before. This is a computationally cheap way to prevent repeat calculations. DynamoDB acts something like a cache.
- If the word has not be searched before, a list of idioms is pulled from S3. These idioms have been scraped from a few websites that list a few thousand idioms. The output is limited by the quality of these idioms and the subsequent step.
- Each idiom is converted to pronunciation form and then the distance between the input word and each word in the idiom is calculated.
- The shortest top 10 distances are outputted and the results are cached.